Comparative Analysis of Parallelization Techniques Applied To Classic Algorithmic Problems
Abstract
This research investigates the effectiveness of different parallelization approaches applied to four fundamental computer science algorithms:
- Fibonacci sequence calculation
- 0/1 Knapsack problem
- Longest Common Subsequence (LCS)
- Longest Palindromic Substring detection
Four distinct implementation strategies were evaluated:
- Naive recursive
- Manual parallelization using std::async
- Dynamic programming with memoization/tabulation
- OpenMP task-based parallelism
Performance analysis was conducted across varying problem sizes using high-precision timing on an Intel i7-14700k 20-core system.
Key Findings:
- Algorithm selection depends critically on problem characteristics
- Dynamic programming excels for most recursive problems due to superior algorithmic complexity
- Parallelization techniques show remarkable effectiveness for embarrassingly parallel problems
- The study reveals important insights about thread management overhead, parallel execution costs, and the necessity of matching parallelization strategy to problem structure
1. Introduction
Parallel computing has become essential in modern software development as sequential processing reaches physical limitations imposed by processor clock speeds and power consumption. This research addresses a fundamental question in parallel algorithm design: when and how should classic algorithms be parallelized to achieve optimal performance? The study examines four representative algorithmic problems that span different computational patterns and parallelization challenges.
The motivation for this work stems from the practical need to understand trade-offs between different parallelization approaches. While theoretical complexity analysis provides guidance, amortization and real-world performance depends on factors such as thread management overhead, memory access patterns, data size, and hardware architecture characteristics. This research provides empirical evidence to guide algorithm selection decisions in parallel computing applications.
2. Background and Motivation
Modern parallel computing encompasses several key paradigms that I explored in this research:
Thread-Based Parallelism
The manual parallelization approach using std::async and std::future implements fork-join parallelism patterns, allowing explicit control over thread creation and synchronization. However, this control comes with the responsibility of careful resource management to prevent exhaustion.
Task-Based Parallelism
OpenMP's task-based programming model provides a higher-level abstraction through its work-stealing scheduler and implicit thread pool management. This approach removes much of the manual thread management burden while maintaining performance.
Algorithmic Optimization
Dynamic programming serves as a crucial baseline, demonstrating how algorithmic improvements can often outperform parallelization efforts. Understanding when to optimize algorithms versus when to parallelize is a key question this research addresses.
Real-World Applications
These parallelization techniques are actively used across industries:
- Financial institutions use parallel dynamic programming for option pricing algorithms
- Graphics processing relies heavily on embarrassingly parallel problems similar to palindrome detection
- Scientific computing applications frequently encounter the recursive problem structures analyzed in this study
3. Methodology
3.1 Algorithm Selection
Four classic algorithms were selected to represent different computational patterns:
- Fibonacci Sequence: Represents simple recursive problems with overlapping subproblems
- 0/1 Knapsack Problem: Demonstrates optimization problems with complex state spaces
- Longest Common Subsequence: Illustrates string processing algorithms with two-dimensional recurrence relations
- Longest Palindromic Substring: Represents geometric/spatial problems amenable to parallel decomposition
3.2 Implementation Approaches
Each algorithm was implemented using four distinct strategies:
1. Naive Recursive
- Baseline implementations using simple recursion without optimization
- Serves as performance baseline
- Demonstrates exponential complexity growth
2. Manual Parallelization
- Custom parallel implementations using
std::asyncandstd::futurefrom C++20 - Includes depth-limiting mechanisms to prevent thread pool exhaustion
- Explicit control over thread creation and synchronization
3. Dynamic Programming
- Optimized implementations using memoization or tabulation
- Eliminates redundant computation entirely
- Utilizes
std::unordered_mapwith custom hash functions for complex key types
4. OpenMP Task-Based
- Production-quality parallel implementations using OpenMP 5.0 task directives
- Leverages OpenMP's sophisticated work-stealing scheduler
- Implicit thread management
3.3 Performance Measurement
High-precision timing was implemented using std::chrono::high_resolution_clock with nanosecond accuracy. Each algorithm execution was measured across multiple problem sizes, with results automatically logged for analysis.
3.4 Experimental Setup
- Hardware: Intel i7-14700k (20 cores, 28 threads)
- Compiler: Intel oneAPI C++ Compiler with OpenMP 5.0 support
- Test Sizes: Fibonacci (n=4,8,16,32,48), Knapsack (n=4,8,16,32), LCS (n=4,8,16,32), Palindrome (n=1000,2000,3000,4000)
4. Results and Analysis
4.1 Overall Performance Characteristics
Performance analysis reveals distinct patterns across the four algorithmic problems:
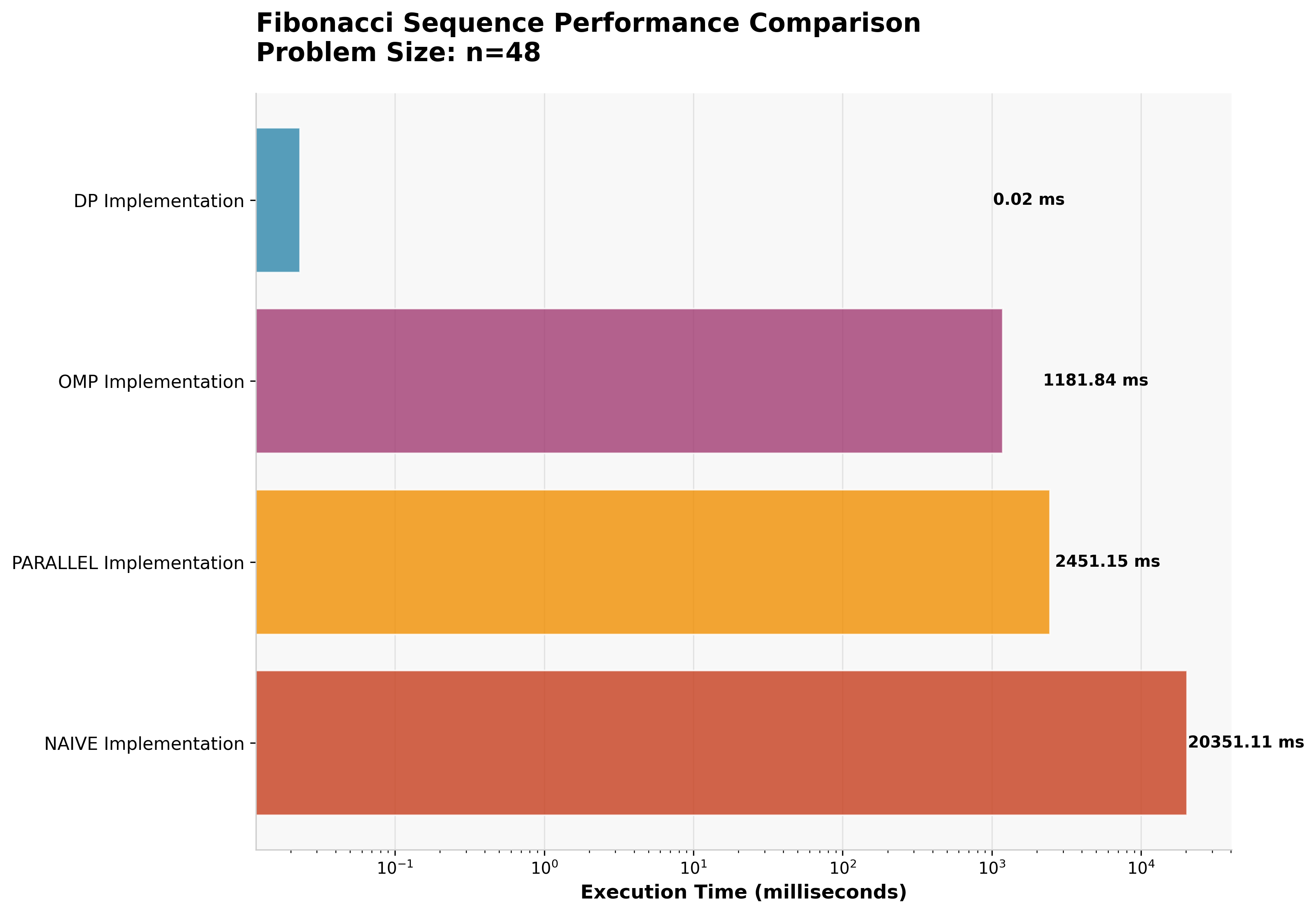
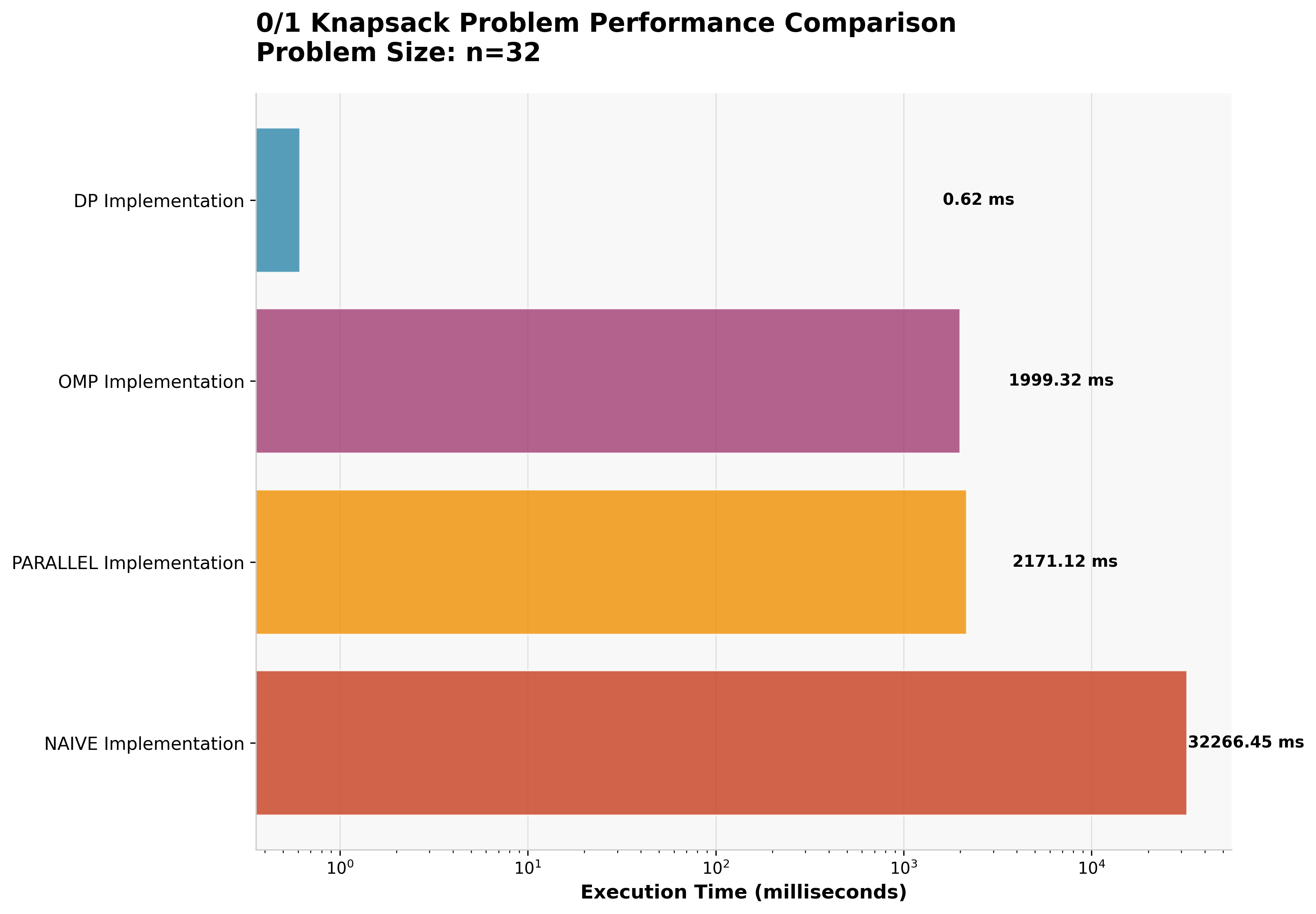
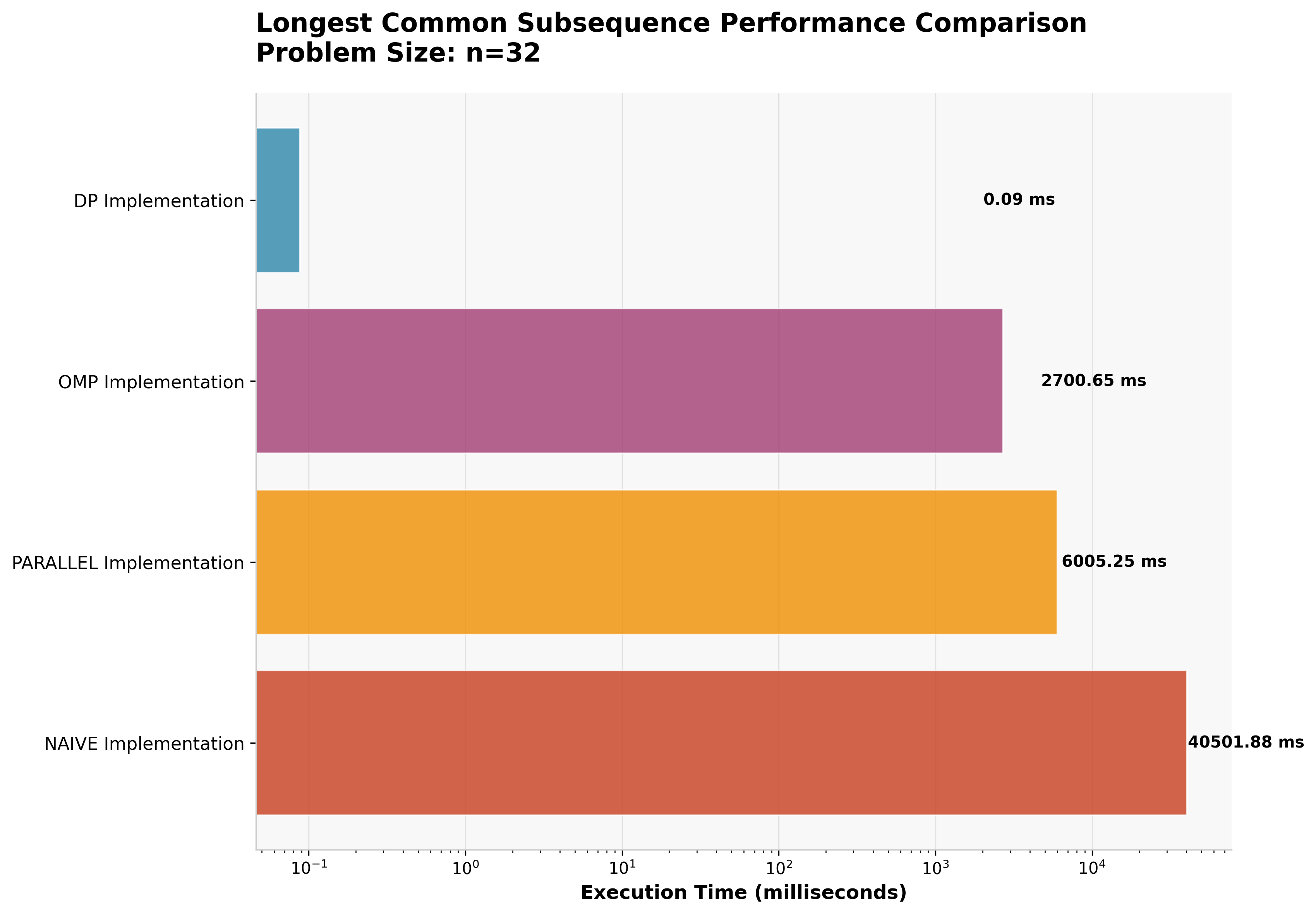
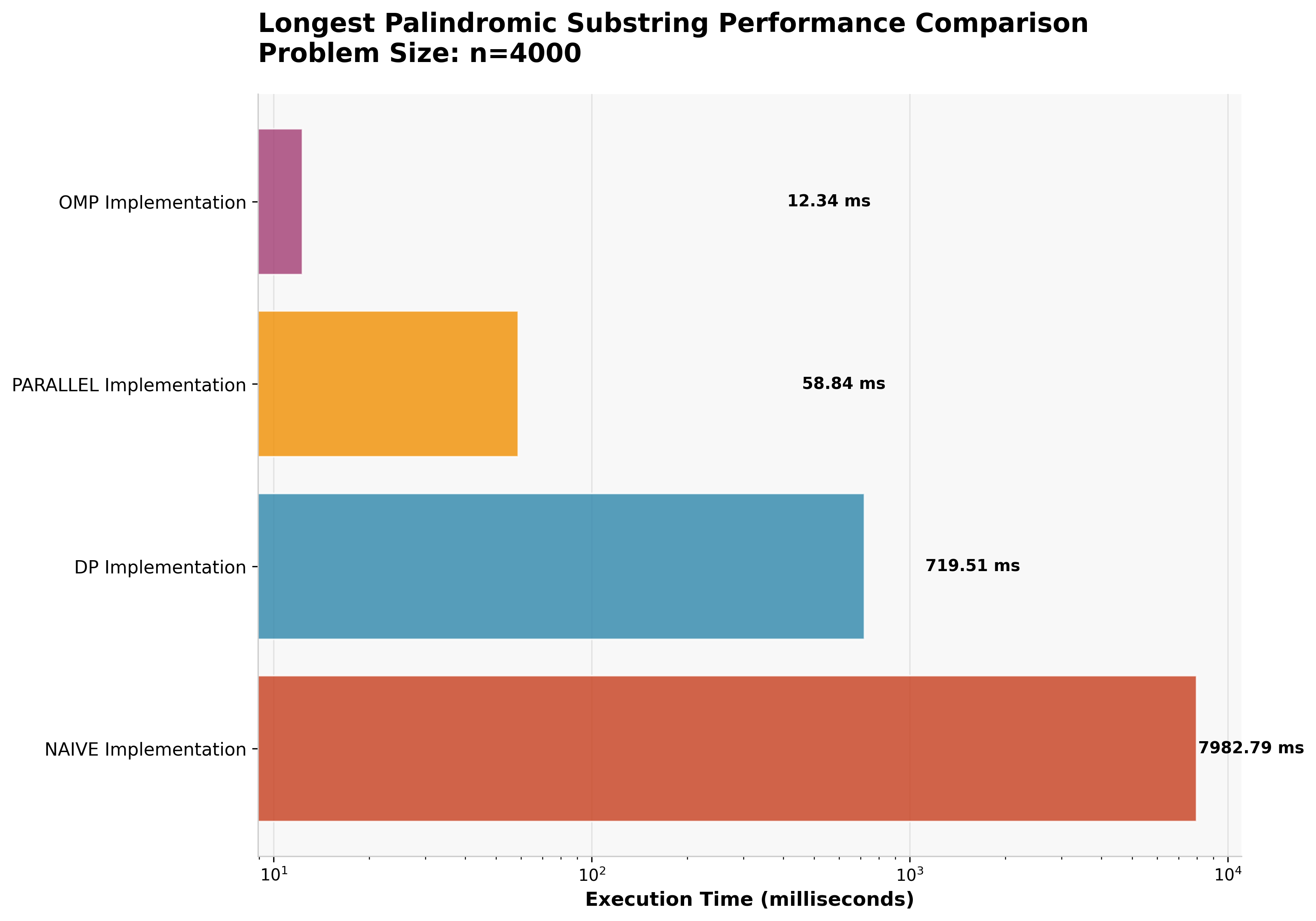
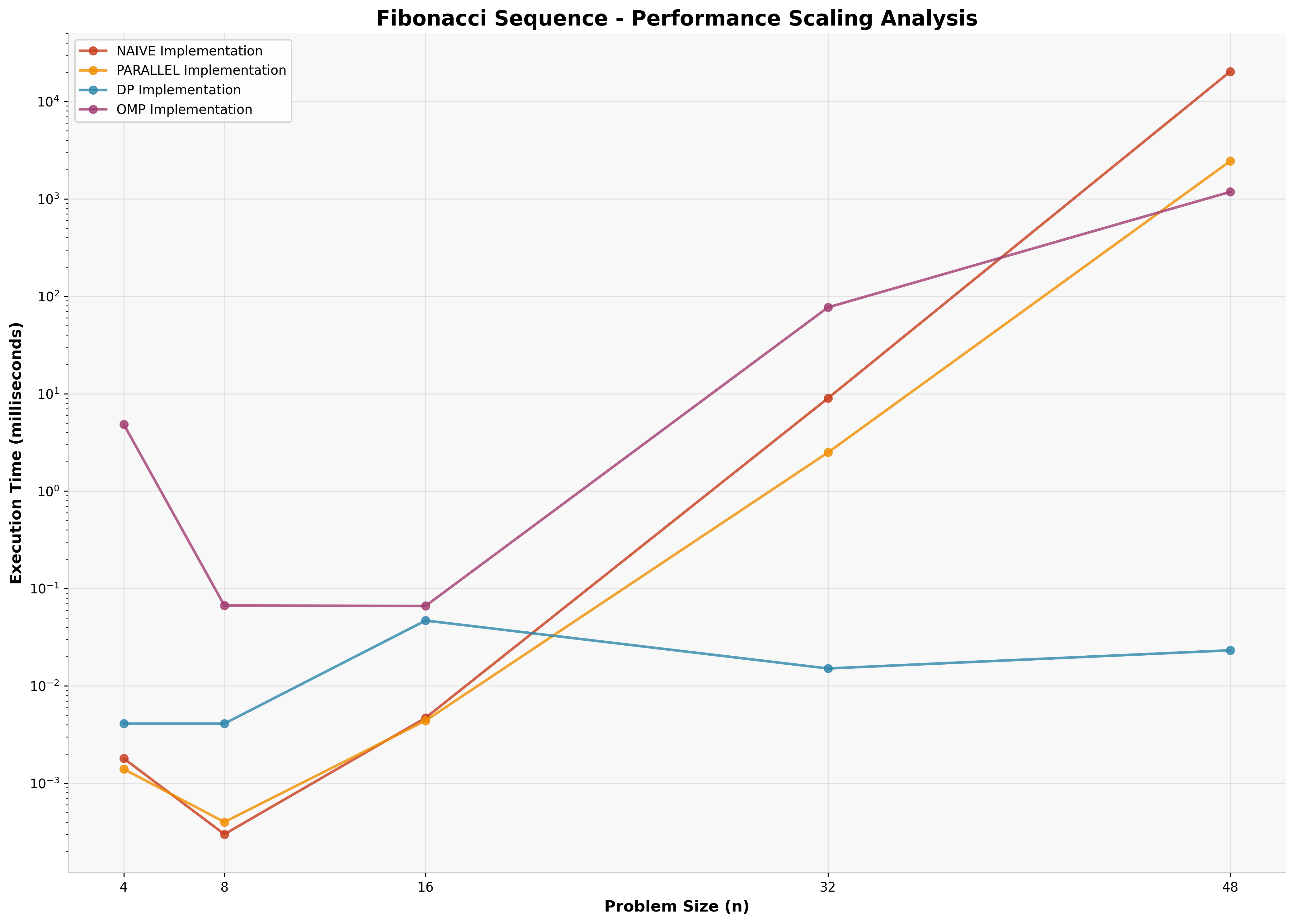
4.2 Fibonacci Sequence Results
For Fibonacci calculation (n=48), the performance hierarchy clearly demonstrates the impact of algorithmic versus parallel optimization.
| Approach | Execution Time | Speedup vs Naive |
|---|---|---|
| Dynamic Programming | 0.023ms | 876,000× |
| OpenMP Parallel | 1,182ms | 17× |
| Manual Parallel | 2,451ms | 8× |
| Naive Recursive | 20,351ms | 1× (baseline) |
Key Insight: The dynamic programming approach achieves a remarkable 876,000× speedup over naive recursion by eliminating redundant computation entirely. This demonstrates that algorithmic optimization fundamentally outperforms parallelization for problems with optimal substructure.
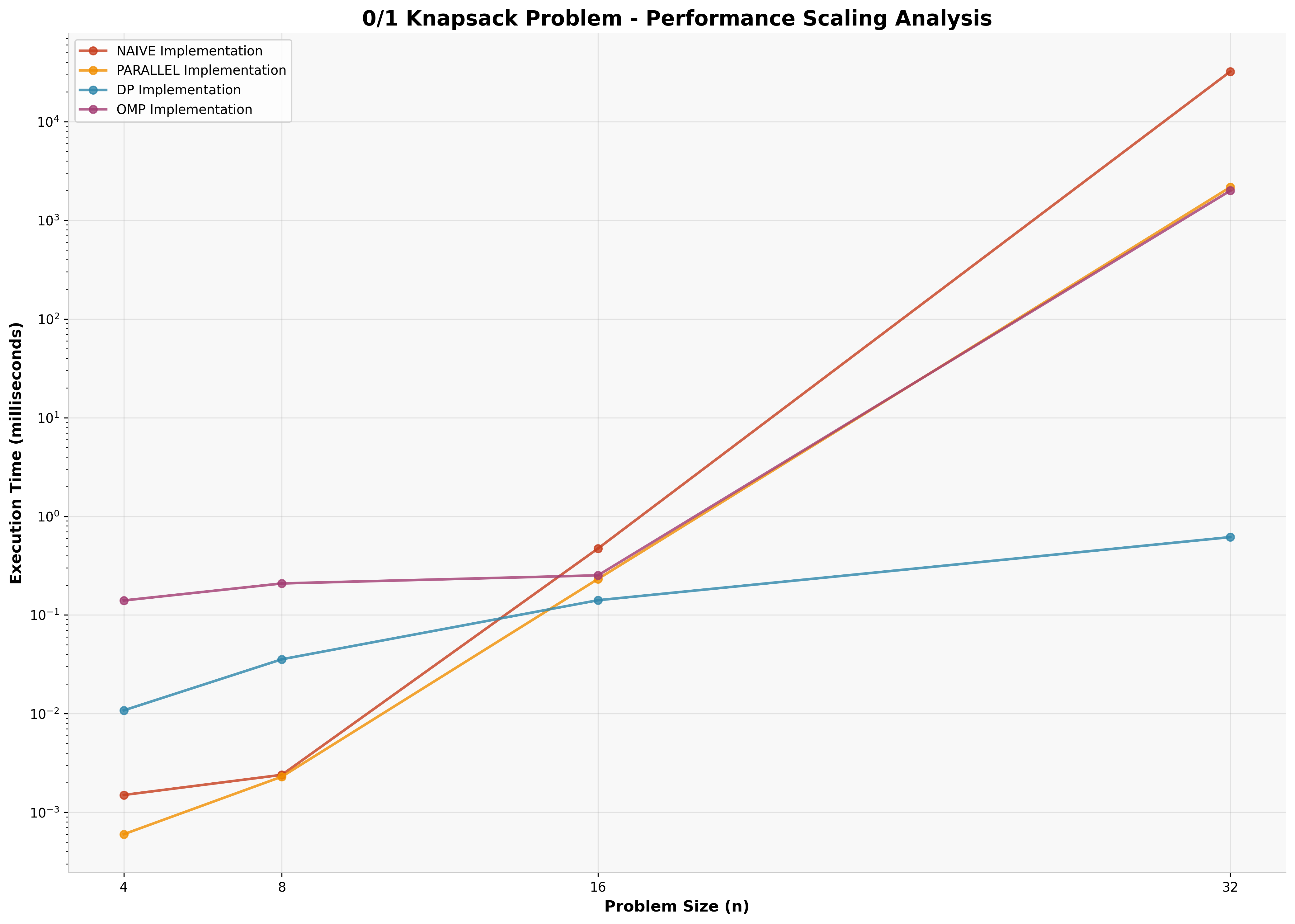
4.3 Knapsack Problem Results
The 0/1 Knapsack problem shows similar patterns, with dynamic programming providing optimal performance for larger problem instances (n=32).
| Approach | Execution Time | Speedup vs Naive |
|---|---|---|
| Dynamic Programming | 0.616ms | 52,370× |
| OpenMP Parallel | 1,999ms | 16× |
| Manual Parallel | 2,171ms | 15× |
| Naive Recursive | 32,266ms | 1× (baseline) |
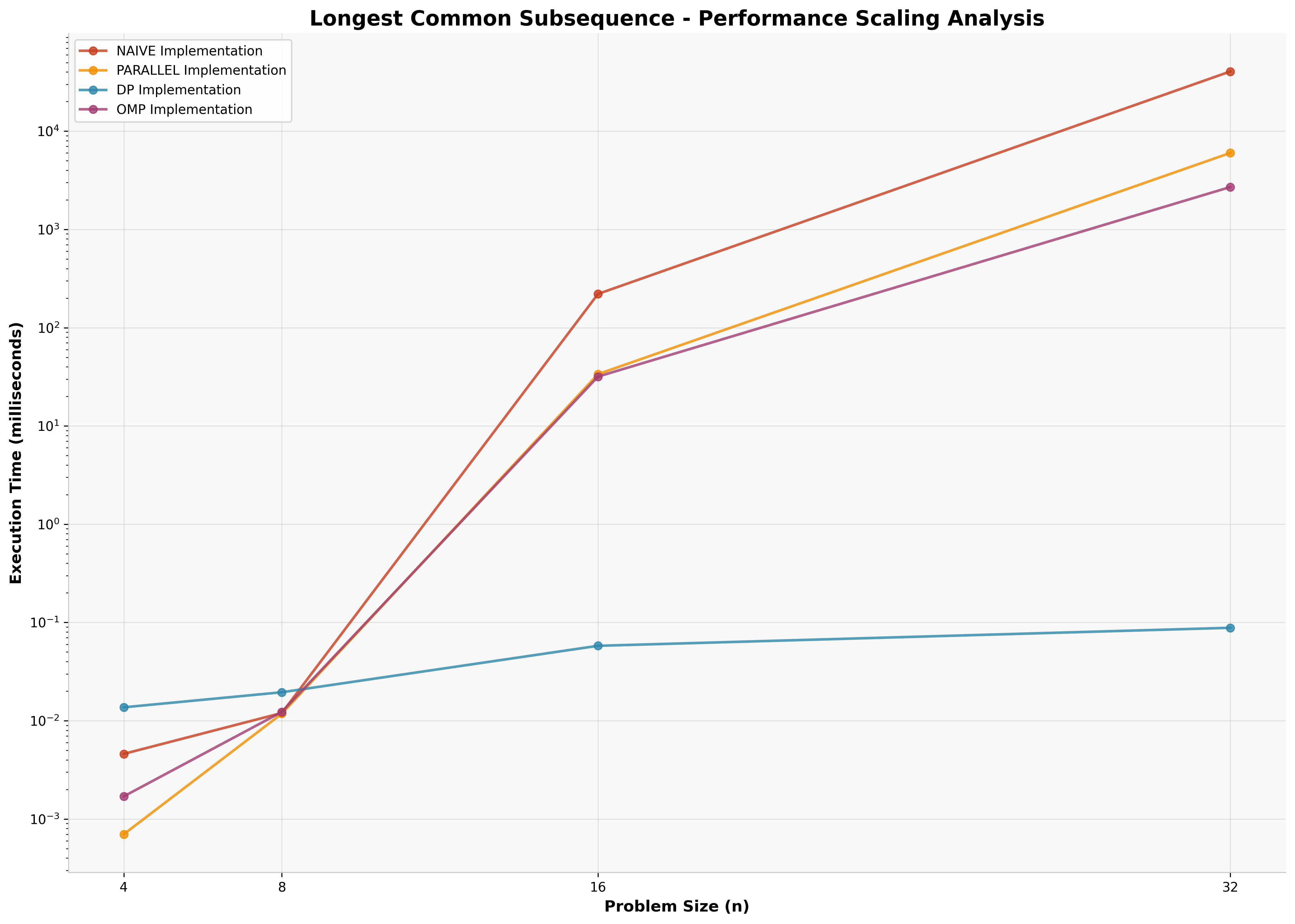
4.4 Longest Common Subsequence Results
LCS results follow the established pattern, with dynamic programming achieving O(m×n) complexity compared to exponential growth in recursive approaches (n=32).
| Approach | Execution Time | Speedup vs Naive |
|---|---|---|
| Dynamic Programming | 0.088ms | 460,250× |
| OpenMP Parallel | 2,701ms | 15× |
| Manual Parallel | 6,005ms | 7× |
| Naive Recursive | 40,502ms | 1× (baseline) |
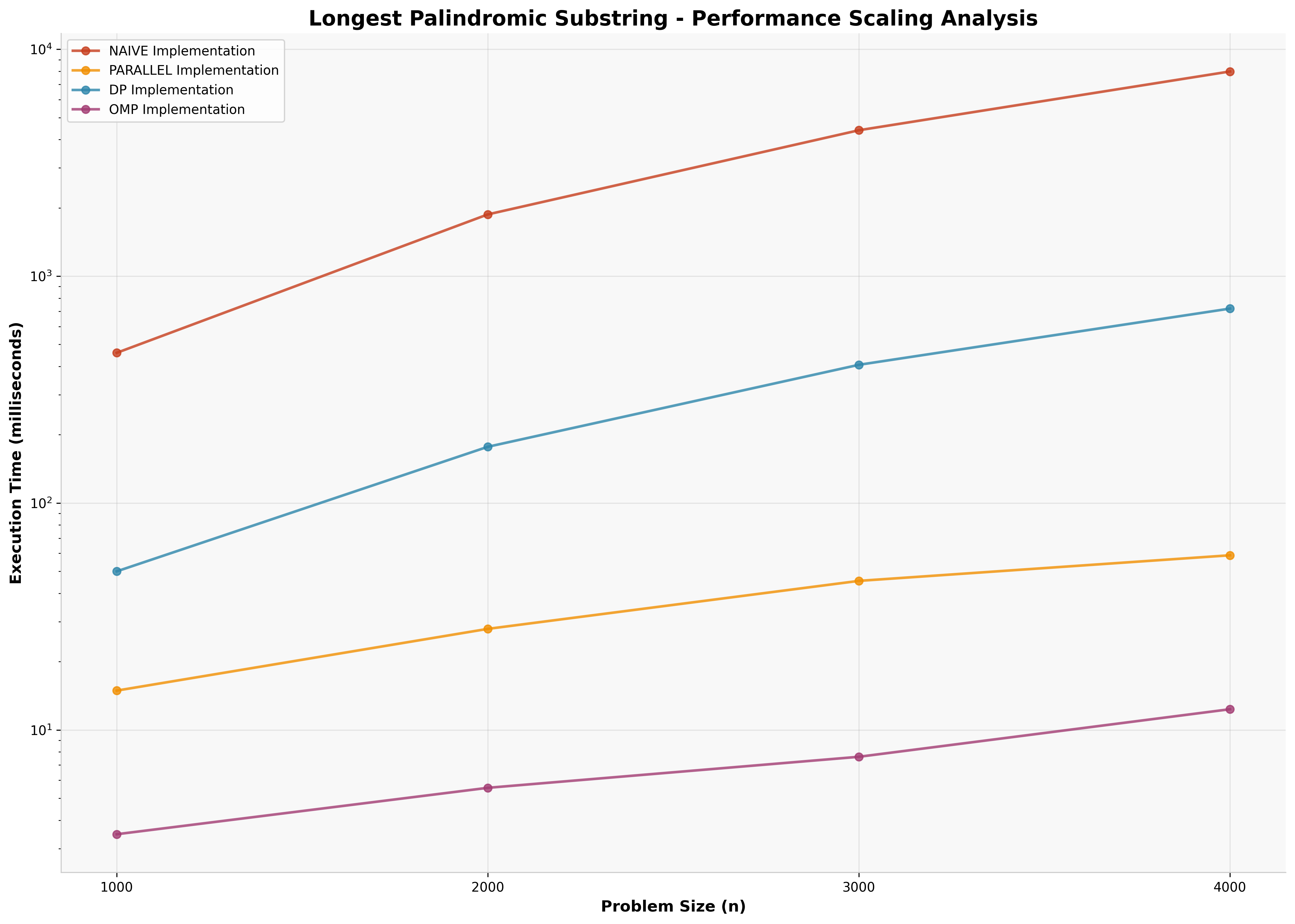
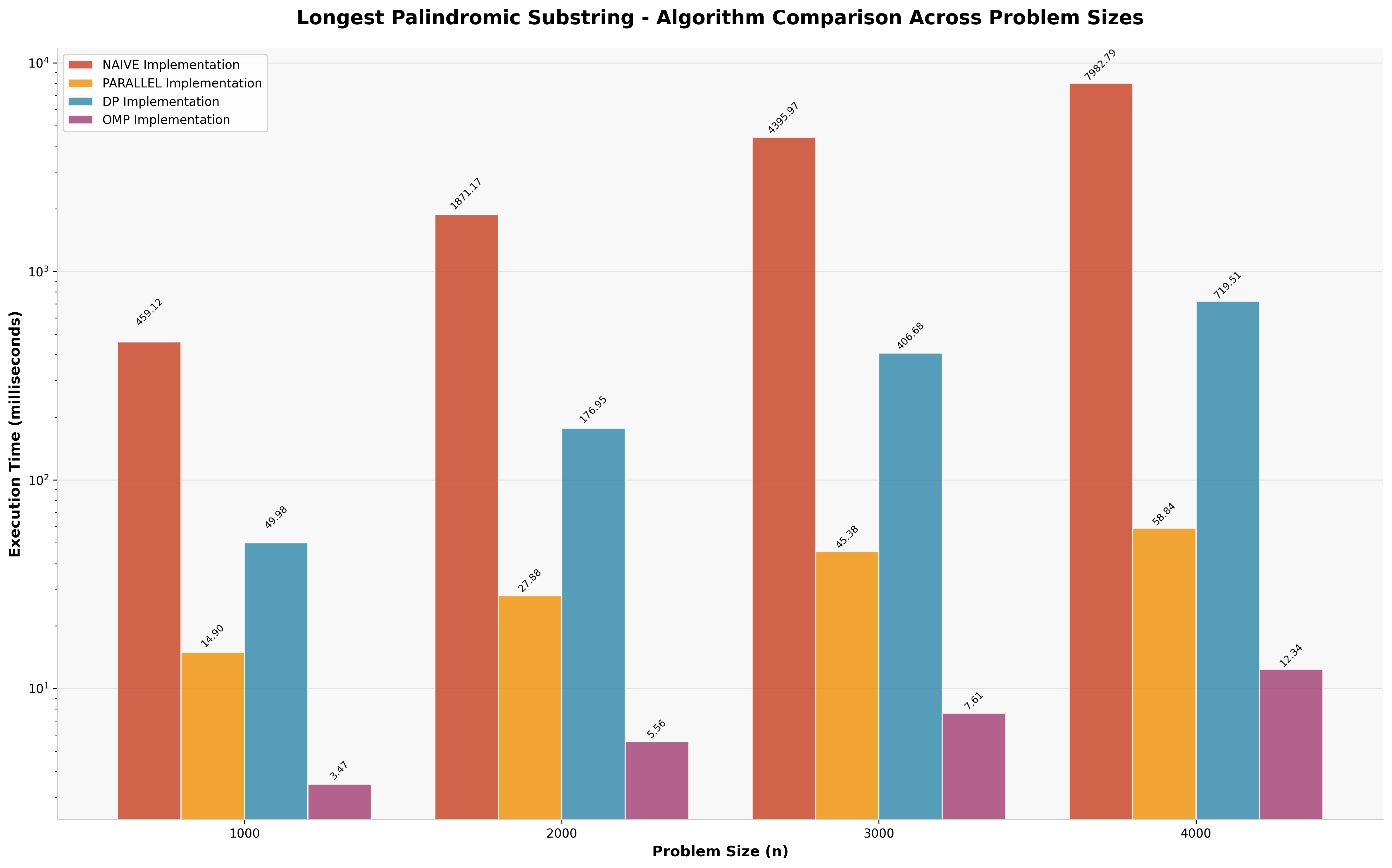
4.5 Palindrome Detection: The Embarrassingly Parallel Exception
The palindrome detection problem reveals a fundamentally different performance landscape where parallelization excels.
| Approach | Execution Time | Speedup vs Naive |
|---|---|---|
| OpenMP Parallel | 12ms | 665× ⚡ |
| Manual Parallel | 58ms | 138× |
| Dynamic Programming | 719ms | 11× |
| Naive Algorithm | 7,983ms | 1× (baseline) |
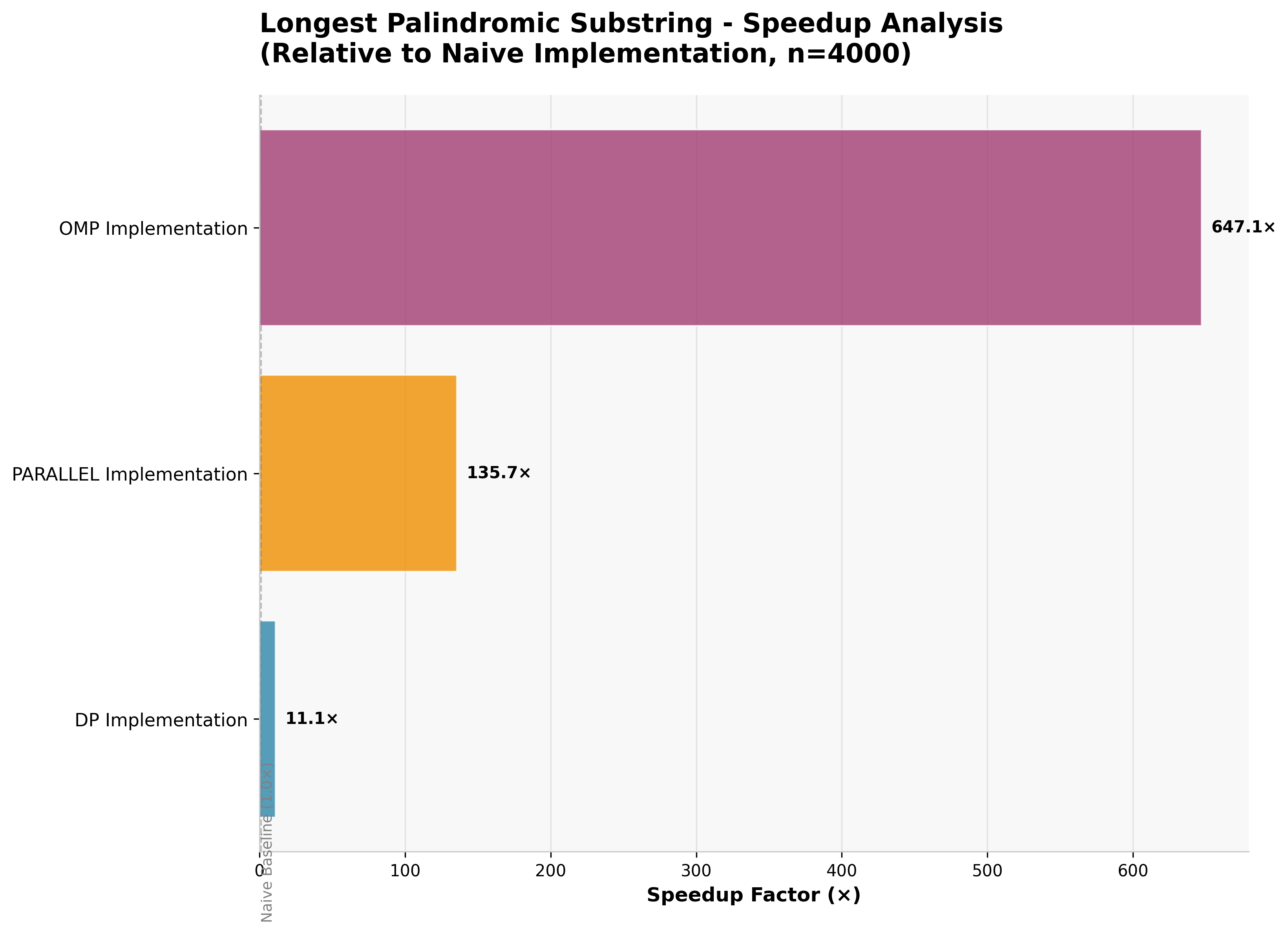
This represents the only case where parallel approaches significantly outperform dynamic programming.
The "expand from center" algorithm for palindrome detection is embarrassingly parallel -- each potential palindrome center can be evaluated independently with minimal inter-thread communication.
Why parallelization wins here:
- Independent evaluation of each potential center
- Minimal shared state between threads
- Balanced workload distribution
- Low communication overhead
4.6 Scaling Analysis
The scaling analysis reveals important insights about when parallelization overhead becomes worthwhile. For smaller problem sizes, the cost of thread creation and management often exceeds the computational benefits, leading to scenarios where even naive sequential implementations outperform parallel approaches.
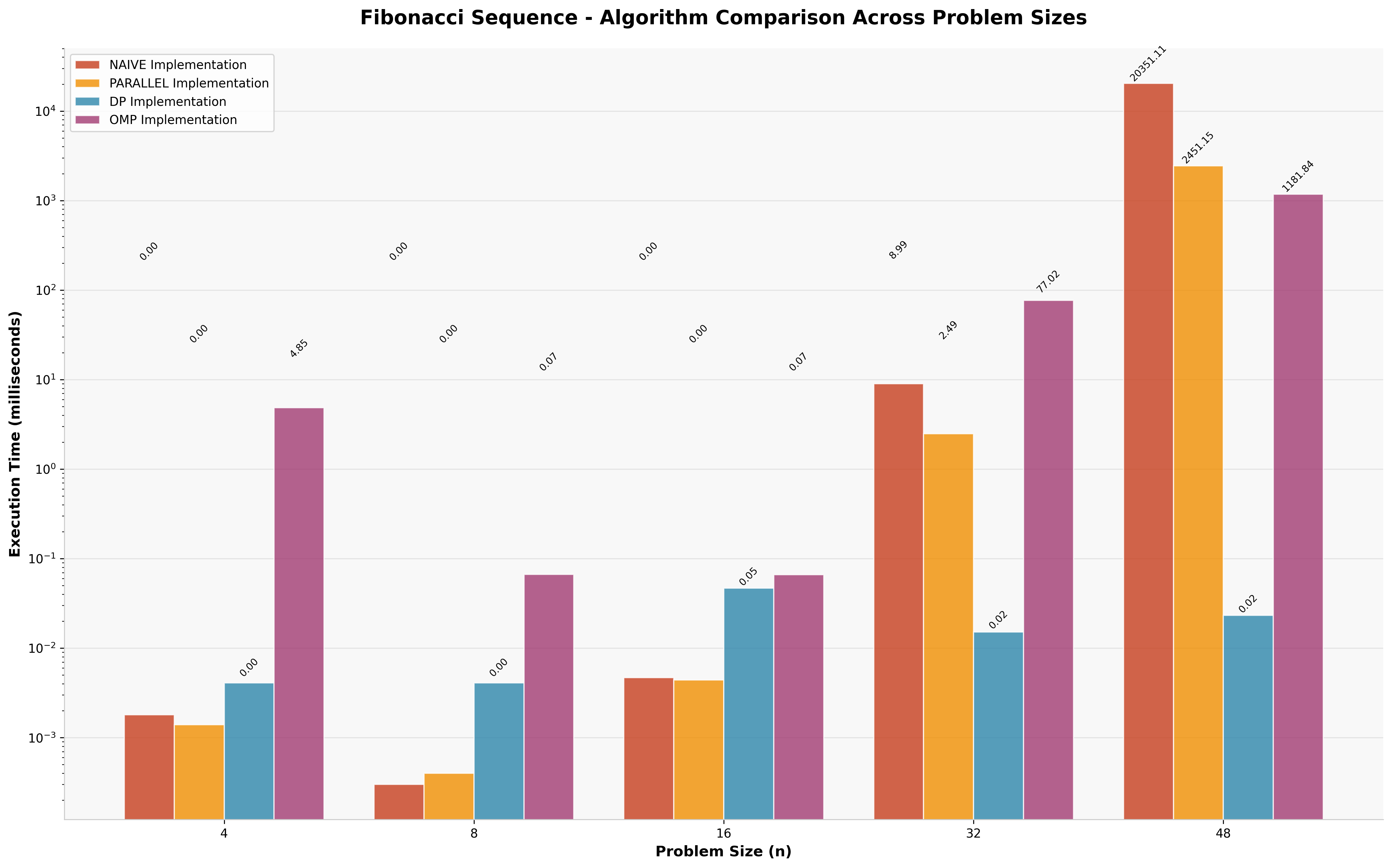
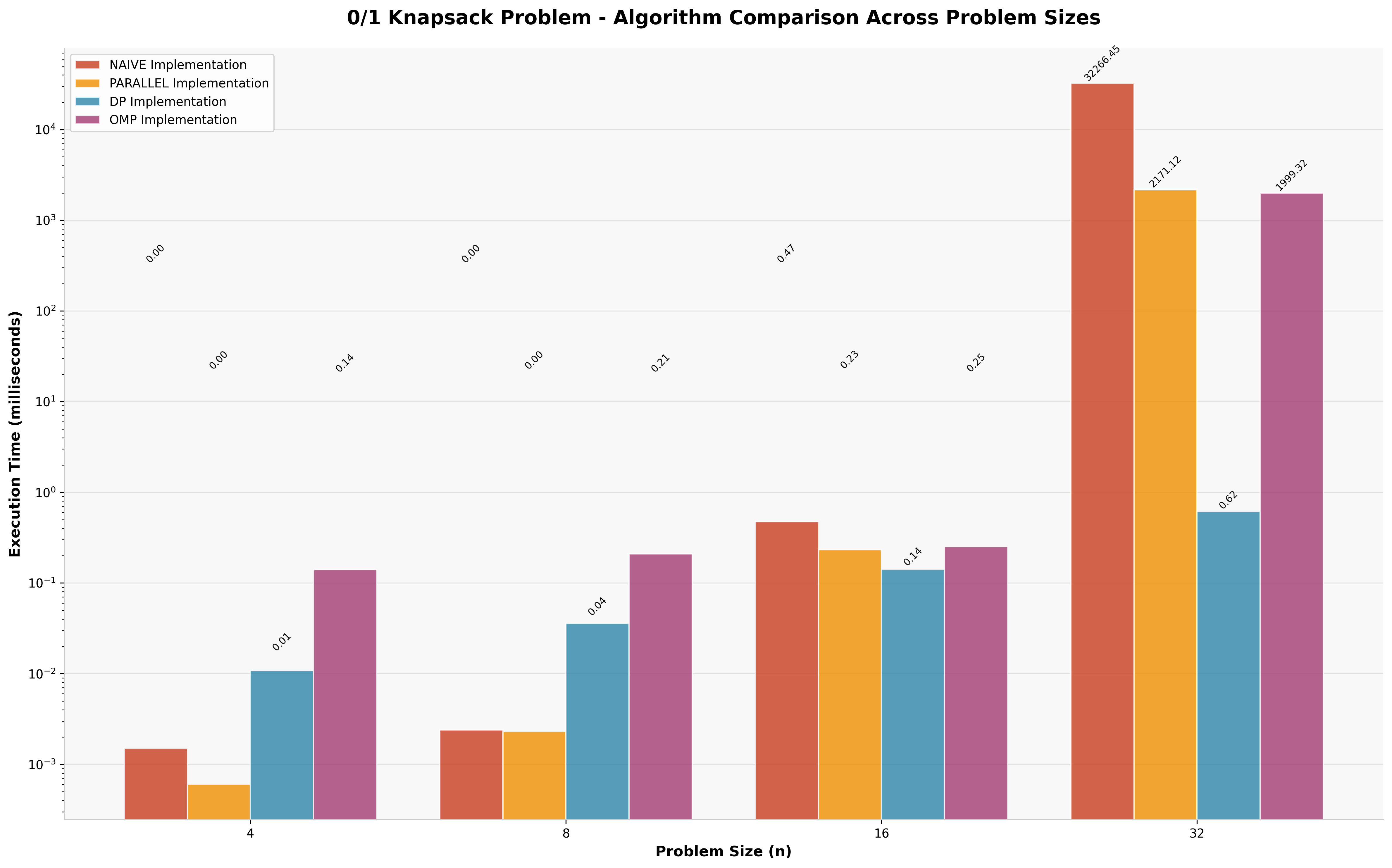
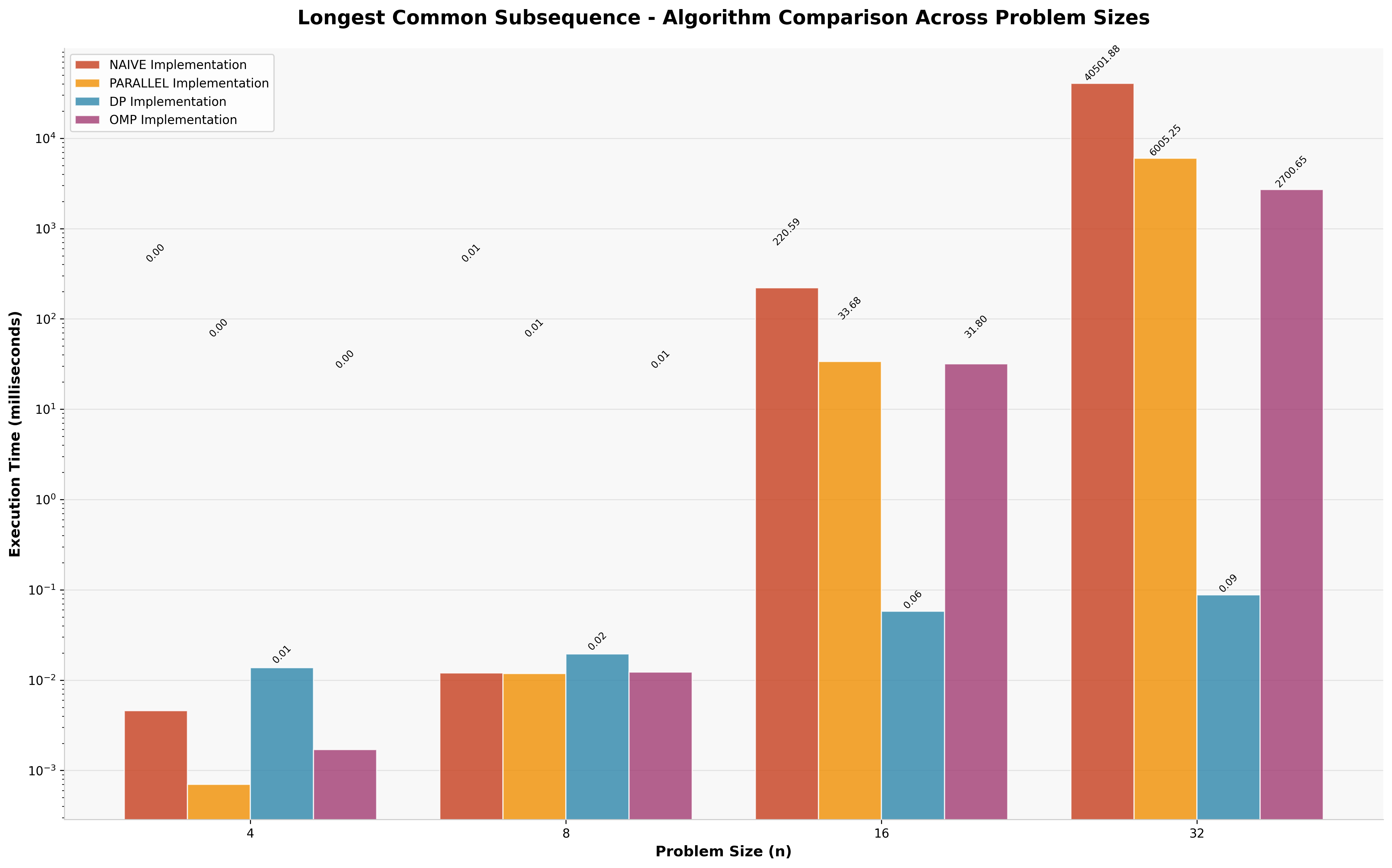
5. Research Experience and Key Insights
5.1 Thread Management Complexity
The research revealed that manual parallelization using std::async requires extremely careful management. The MAX_PARALLEL_DEPTH constant proved critical -- incorrect tuning leads to thread pool exhaustion, program halts, and potential deadlocks. This parameter must be calibrated based on:
- Available system threads
- Problem-specific recursion depth
- Memory constraints
- Thread creation overhead
5.2 OpenMP Advantages and Limitations
OpenMP's thread pool and work-stealing scheduler provided significant advantages over manual thread management. The runtime automatically manages thread allocation and provides efficient task distribution. However, OpenMP does not automatically handle overhead optimization -- developers must still implement sequential cutoffs and appropriate problem decomposition strategies.
The constant communication between threads in OpenMP implementations adds measurable latency, particularly for problems with fine-grained parallelism. This overhead is acceptable for computationally intensive tasks but can dominate execution time for lightweight operations.
5.3 The Primacy of Algorithmic Optimization
A crucial insight from this research is that proper algorithmic approaches (particularly dynamic programming) are far superior to simply "throwing threads at problems". The dramatic performance differences observed -- often orders of magnitude -- demonstrate that algorithmic complexity reduction should be the first optimization strategy considered.
5.4 Embarrassingly Parallel Problems
The palindrome detection results highlight the importance of problem structure in parallelization decisions.
Embarrassingly parallel problems -- where work can be decomposed with minimal inter-thread communication -- represent the ideal use case for parallel computing techniques.
The palindrome algorithm's superior parallel performance stems from:
- ✓ Independent evaluation of each potential center
- ✓ Minimal shared state between threads
- ✓ Balanced workload distribution
- ✓ Low communication overhead
6. Limitations
This research has several important limitations that should be acknowledged:
6.1 Limited Algorithm Scope
The study examines only four algorithmic problems, which, while representative, cannot capture the full spectrum of parallel computing applications. More comprehensive analysis would benefit from examining:
- Graph algorithms (shortest path, minimum spanning tree)
- Sorting algorithms (merge sort, quicksort variants)
- Matrix operations (multiplication, decomposition)
- Numerical integration methods
- Machine learning algorithms (K nearest, Gradient Descent)
6.2 Single Hardware Platform
All experiments were conducted on a single Intel architecture (i7-14700k). Performance characteristics may differ significantly on:
- AMD processor architectures
- ARM-based systems
- Systems with different core counts and memory hierarchies
6.3 Limited Problem Sizes
Computational constraints limited the maximum problem sizes tested. Larger-scale analysis might reveal different performance crossover points and scaling behaviors.
6.4 Threading Model Limitations
The study focused on shared-memory parallelism using OpenMP and standard library threading. Distributed computing approaches (MPI, cluster computing, CUDA) were not evaluated, limiting applicability to large-scale computational problems.
7. Future Work
Given additional time and resources, several research directions would provide valuable insights:
7.1 Modern C++ Parallel Algorithms
Investigation of C++17/20 std::execution policies would provide insight into standardized parallel algorithm implementations. These standardized approaches could offer better portability and potentially superior performance through compiler optimizations.
7.2 GPU Computing Integration
CUDA implementation would enable evaluation of massively parallel approaches:
- Fibonacci: Parallel matrix exponentiation methods
- Knapsack: Parallel dynamic programming with shared memory optimization
- LCS: 2D parallel wavefront algorithms
- Palindrome: Massively parallel center expansion
7.3 Extended Algorithm Portfolio
Broader algorithmic coverage would strengthen the research conclusions:
- Merge Sort: Comparison of divide-and-conquer parallel strategies
- Matrix Multiplication: Evaluation of blocked parallel algorithms
- Graph Algorithms: Analysis of parallel breadth-first search and shortest path algorithms
- Numerical Methods: Investigation of parallel integration and differential equation solvers
7.4 Performance Profiling and Memory Analysis
Advanced profiling tools could provide deeper insights into:
- Cache performance and memory access patterns
- Thread synchronization overhead quantification
- Memory bandwidth utilization
- Power consumption analysis
7.5 Hybrid Approaches
Investigation of algorithms that combine multiple parallelization strategies:
- OpenMP + CUDA hybrid implementations
- Dynamic programming with parallel subproblem evaluation
- Adaptive algorithms that select optimization strategy based on problem characteristics
8. Conclusions
This research provides empirical evidence for several important principles in parallel algorithm design:
8.1 Algorithmic Optimization Primacy
For most problems with optimal substructure, dynamic programming approaches provide superior performance compared to parallelization of naive algorithms.
The orders-of-magnitude performance improvements observed (up to 876,000× for Fibonacci) demonstrate that algorithmic complexity reduction should be the primary optimization strategy.
8.2 Problem Structure Determines Parallel Suitability
The palindrome detection results clearly demonstrate that embarrassingly parallel problems can achieve significant benefits from parallelization, even outperforming algorithmically superior approaches.
Takeaway: Problem structure analysis should guide parallelization decisions.
8.3 Thread Management Complexity
Manual parallelization requires sophisticated management strategies to prevent resource exhaustion and deadlocks. OpenMP provides valuable abstractions but still requires careful consideration of overhead and sequential cutoffs.
8.4 Hardware-Software Co-design
Effective parallel algorithm implementation requires understanding of underlying hardware characteristics:
- Core count and thread availability
- Memory hierarchy and cache sizes
- Thread creation costs
- Communication overhead
Final Thoughts
The research contributes to the broader understanding of when and how to apply parallel computing techniques effectively. Rather than advocating for universal parallelization, the results emphasize the importance of matching optimization strategy to problem characteristics and computational requirements.
Practical implications for developers:
- Systematically analyze problem structure before parallelization efforts
- Consider hybrid approaches combining algorithmic optimization with targeted parallelization
- Match the optimization strategy to the problem's inherent structure
Future directions:
- Develop automated tools for parallel algorithm selection
- Create hybrid approaches that adaptively combine different optimization strategies
- Build systems that adjust based on runtime problem characteristics and system resources